
登录新浪财经APP 搜索【信披】查看更多考评等级
7月2日,万业企业(SH600641,前收盘价11.30元,市值105.2亿元)的一则公告引发了市场的广泛关注。公司预计2024年上半年净利润将出现约4900万元的亏损,与去年同期的1.186亿元净利润形成鲜明对比。万业企业的业绩“大变脸”,将责任归咎于金融市场的波动和投资高风险的金融衍生产品。
转自:前瞻产业研究院
行业主要上市公司:百川智能(A04400.SH)、昆仑万维(300418.SZ)、拓维信息(002261.SZ)、浪潮信息(000977.SZ)、科大讯飞(002230.SZ)等
本文核心数据:中国大语言模型产业链;中国代表性大语言模型产品商业化进程;大语言模型市场规模及测算;大语言模型市场规模预测等
行业概况
1、定义
大规模语言模型(Large Language Models,LLM),也称大语言模型或大型语言模型,是一种由包含数百亿以上参数的深度神经网络构建的语言模型,通常使用自监督学习方法通过大量无标注文本进行训练。自2018年以来,Google、OpenAI、Meta、百度、华为等公司和研究机构都相继发布了包括BERT,GPT-3等在内的大语言模型,随后几年来,大语言模型呈现爆发式的增长。用户可以使用自然语言与系统交互,从而实现包括问答、分类、摘要、翻译、聊天等从理解到生成的各种任务。大规模语言模型展现出了强大的对世界知识掌握和对语言的理解能力。
2、大语言模型构建流程
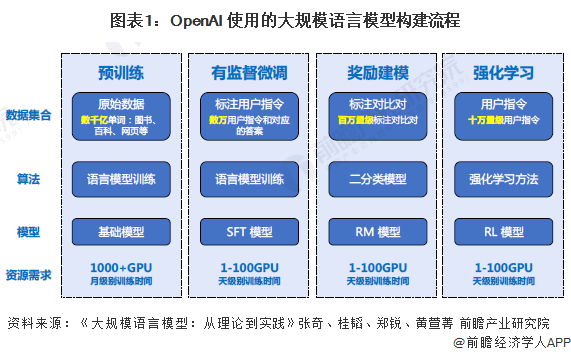
根据OpenAI 联合创始人Andrej Karpathy在微软Build 2023大会上所公开的信息,OpenAI所使用的大规模语言模型构建流程如下图所示。主要包含四个阶段:预训练、有监督微调、奖励建模、强化学习。这四个阶段都需要不同规模数据集合以及不同类型的算法,会产出不同类型的模型,同时所需要的资源也有非常大的差别。
3、产业链剖析
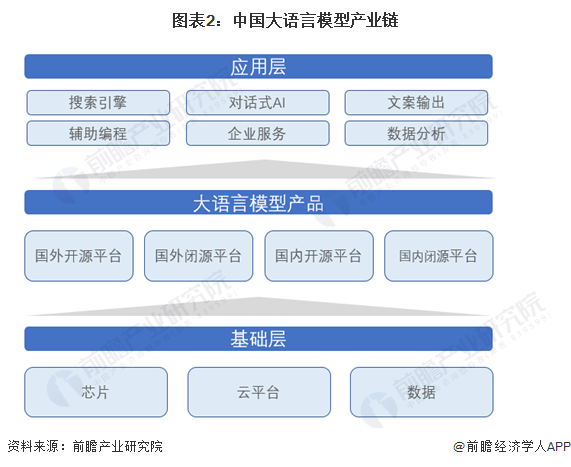
从产业链角度来看,大语言模型产业链主要分为三部分,分别为基础技术层、大语言模型产品以及应用层。基础层包括芯片、云平台、数据等基础技术和数据要素,大语言模型产品目前可分为四大类,分别为国外开源平台、国外闭源平台、国内开源平台、国内闭源平台。在落地应用层面,主要应用包括搜索引擎、对话式AI、文案输出等。
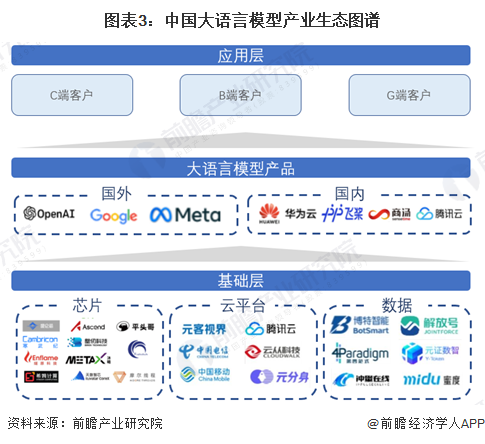
从产业链各环节的参与者来看,核心环节大语言模型平台的建设由于技术密集程度较高、训练成本巨大,因此,仅有部分少数互联网巨头可参与其中,搭建自研大语言模型凭条。代表性企业包括华为、百度、商汤、腾讯。产业链上游技术层面中,包括芯片生产、云平台搭建以及数据要素收集等,这些领域技术壁垒同样较高,参与者均为互联网、计算机行业头部公司。
行业发展历程:行业发展突飞猛进
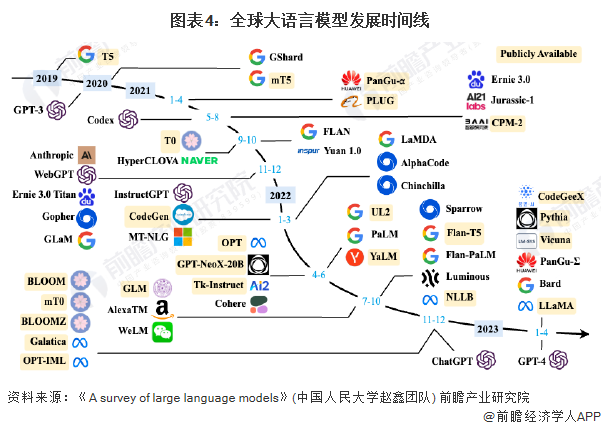
大语言模型的发展历程虽然只有短短六年的时间,但是发展速度相当惊人,迄今为止,国内外有超过百种大模型相继发布。下图给出了2019年至2023年比较有影响力并且模型参数量超过100亿的大语言模型的发展时序。
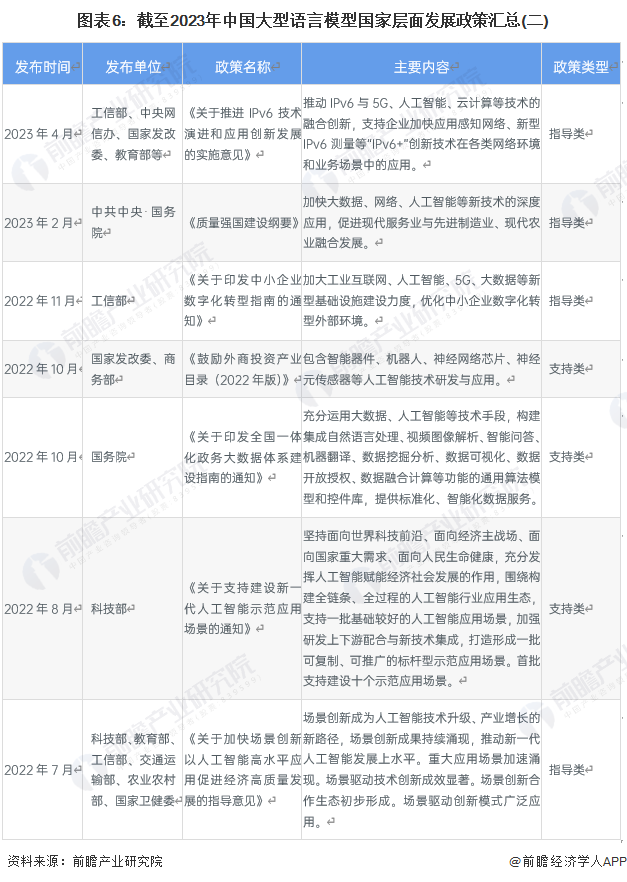
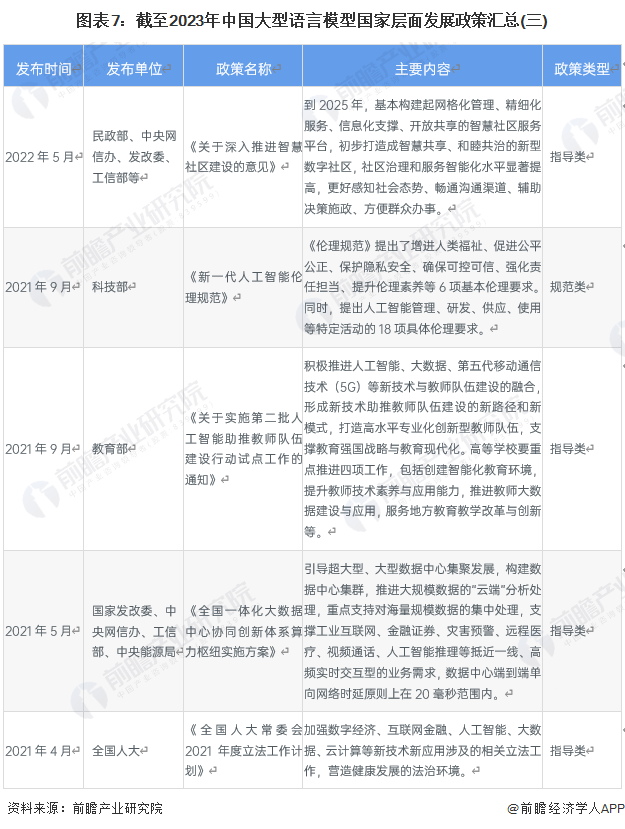
行业政策背景:从技术供给端对行业予以支持
我国大力支持大型语言模型的发展,截至2023年,我国直接支持大型语言模型发展的政策数量相对较少,且主要集中在2023年发布,更多是从人工智能技术以及算力设备等角度支持行业发展。具体如下表所示:

行业发展现状
1、大语言模型技术路线分析
根据技术路线不同,大语言模型可分为Encoder-Decoder(或者Encoder-Only)和Decoder-Only,其中,Encoder-Decoder或者Encoder-Only训练方式为Masked语言模型,代表性模型包括ELMo,BERT,RoBERTa,DistilBERT,BioBERT,XLM,Xlnet,ALBERT,ELECTRA,T5,XLM-E,ST-MoE,AlexaTM;Decoder-Only训练方式为自回归语言模型,代表模型包括GPT-3,OPT,PaLM,BLOOM,GLM,MT-NLG,GLaM,Gopher, chinchilla,LaMDA,GPT-J,LLaMA,GPT-4,BloombergGPT等。
2020年后,Encoder-Only技术基本不在发展,近年来,Encoder-Decoder类型技术路线较多。Encoder-Decoder模型相比Encoder-Only模型,通常具有更强的序列学习和生成能力,尤其擅长实现输入序列到输出序列的结构映射,所以在机器翻译、文摘生成和聊天机器人等任务上有更好的应用前景。但Encoder-Only的模型结构简单,training和inference速度更快,在一些简单分类或标注任务上也具有优势。

2、大语言模型技术原理
在自然语言处理(NLP)领域,预测下一个词汇的任务对于许多应用至关重要。在Transformer架构问世之前,递归神经网络(RNN)是进行此类预测的常用工具。但如果RNN仅依赖于前一个词汇来做出预测,它可能无法充分利用丰富的上下文信息。当RNN需要考虑整个句子或整篇文章中的大量词汇时,模型的复杂性会显著增加。例如,在句子“我们用这个模型来做问答系统”中,确定“这个模型”所指的具体含义需要依赖于整个句子的上下文。RNN在处理需要广泛上下文信息的复杂问题时可能会遇到挑战。这是因为RNN的预测能力受限于其递归结构,这使得它难以同时处理长距离依赖和复杂的上下文关系。
Transformer模型的出现为解决这些问题提供了新的思路。与RNN相比,Transformer模型通过自注意力机制能够更好地捕捉长距离依赖关系,并且能够并行处理整个输入序列,从而提高了处理速度和效率。这使得Transformer在需要广泛上下文信息的任务中,如文本生成、机器翻译和问答系统等,表现出色。2017年,Vaswani等人在论文"Attention is All You Need"中提出了具有颠覆性意义的Transformer模型。与之前的模型不同,Transformer能够并行处理输入数据,利用更大的数据集,最重要的是,它通过注意力机制从上下文中学习单词的含义,因此,Transformer模型现在被更广泛地应用于大语言模型当中。
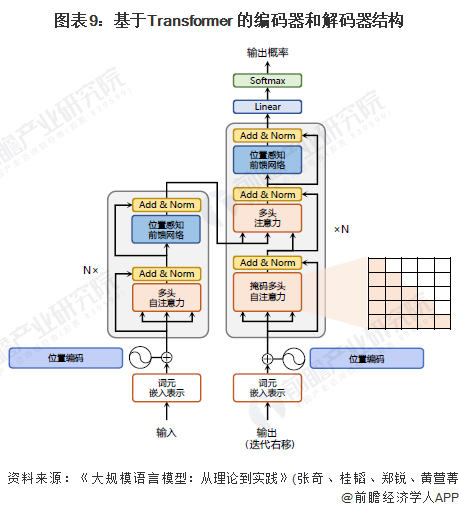
随着基于Transformer各类语言模型的发展以及预训练微调范式在自然语言处理各类任务中取得突破性进展,从2020年OpenAI发布GPT-3开始,大语言模型研究也逐渐深入。虽然大语言模型的参数量巨大,通过有监督微调和强化学习能够完成非常多的任务,但是其基础理论也仍然离不开对语言的建模。Transformer结构完全通过注意力机制完成对源语言序列和目标语言序列全局依赖的建模,当前几乎全部大语言模型都是基于Transformer结构。基于Transformer结构的编码器和解码器结构如下图所示,左侧和右侧分别对应着编码器(Encoder)和解码器(Decoder)结构。它们均由若干个基本的Transformer块(Block)组成(对应着图中的灰色框)。这里N×表示进行了N次堆叠。
3、大语言模型商业化探索进程
截至2024年,中国的大型语言模型(LLMs)在商业化进程中表现出显著的活力和创新。百度的文心一言在智能办公、旅行服务、电商直播、政务服务和金融服务等多个领域实现应用,技术迭代迅速,用户规模庞大。讯飞星火在智能办公上优势明显,2024年4月,公司推出了业界性能最优的130亿参数的大模型,在效果损失仅3%以内的情况下,输出效率、语义理解准确率等均得到提升,在讯飞星火大语言模型的飞速发展下,讯飞自有的硬件产品也受到消费市场的关注,搭载讯飞星火的讯飞智能办公本、讯飞听见、讯飞智能录音笔以及讯飞AI学习机等销量不断攀升。阿里巴巴的通义千问以其开源策略和高性能,在中文大模型领域占据一席之地,推动了低成本、易于部署的商业化解决方案。整体来看,中国的LLMs正通过技术创新、行业合作和安全合规等多维度努力,加速推动AI技术的商业化落地和产业智能化转型。

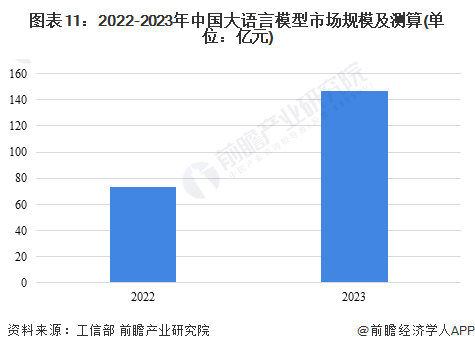
4、大语言模型市场规模分析
2023年末,根据我国工信部数据,2023年全年我国语言大模型市场规模实现较快提升,应用场景不断丰富,增长率突破100%。据统计,2023年,我国大语言模型市场规模为147亿元。
行业竞争格局:参与者众多,竞争激烈
1、行业整体竞争格局
现阶段,我国大型语言模型可以分为四大竞争派系,分别为互联网公司、AI公司、学术及科研机构以及行业专家团队初创公司,其中,互联网公司主要是百度、阿里、腾讯、华为等互联网大厂,核心竞争优势是汇集了大量高端人才,同时,平台技术发展相对全面、快速。AI公司主要是澜舟科技、昆仑万维、商汤科技等以AI研发及利用为主的科技公司,其核心优势是主业专精于人工智能,相比互联网公司,技术优势更加明显。学术、科研机构包括清华、北大、复旦、中科院等国内一流高校以及智源研究院、IDEA研究院等科研机构,主要优势是学术氛围浓厚,通常行业第一手技术发源于此。行业专家品牌则是以一些AI专家带领的团队所研发出的产品为核心,通常,一个团队在短期内主攻一款产品,相比其他竞争派系,AI专家团队研发的产品在创新、突破方面做得更好,C端反馈好评度较高,盈利目的性就目前来看,略弱于互联网公司产品。
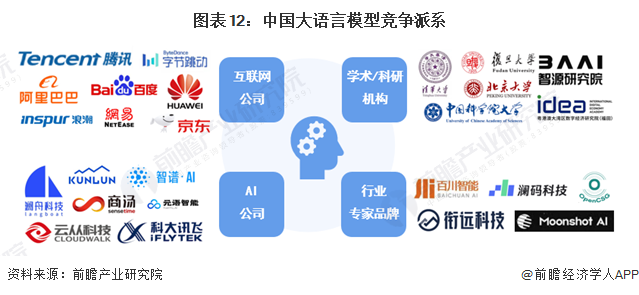
2、细分领域竞争格局
知识储备、长文本阅读能力均是大语言模型的核心竞争力之一,总体来看,在知识储备领域,百川3领先于全行业,单项评分高达82分;长文本阅读能力方面,通义千问以71.8评分领先于选行业。其他大模型中,讯飞星火代码能力突出、传统安全领域MiniMax-abab6.1得到较高评分。

注:根据SuperCLUE官网的信息,SuperCLUE基础十大能力结构包含四个能力象限,包括语言理解与生成、知识理解与应用、专业能力和环境适应与安全性,进而细化为10项基础能力,包括1)语言理解与抽取;2)闲聊;3)上下文对话;4)生成与创作;5)知识与百科;6)代码;7)逻辑与推理;8)计算;9)角色扮演;10)安全。
行业发展前景及趋势预测
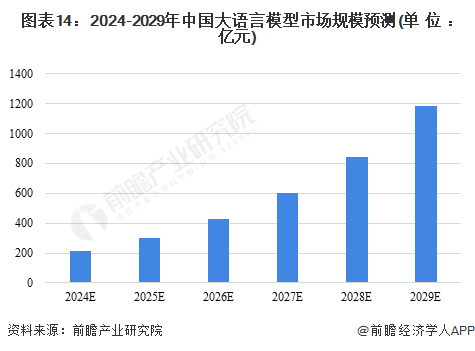
1、大语言模型市场规模预测
语言大模型能够模仿人类的对话和决策能力,是率先实现技术突破和应用落地的大模型,也是当下人工智能的“主赛道”。目前,语言大模型在金融、医疗、教育、工业、游戏、法律等多个行业得到了广泛的应用。前瞻初步测算,到2027年,我国大语言模型市场规模将达到600亿元,到2029年将达到1186亿元,年复合增速在40%以上。
2、大语言模型发展趋势预测
大型语言模型(LLMs)的发展趋势预示着向更大规模、多模态交互、行业定制化、增强的可解释性、强化的安全性与隐私保护、跨语言能力、开源协作、商业化服务、硬件协同优化,以及法规与伦理框架的构建方向发展。这些趋势将共同推动LLMs在提升性能、拓宽应用场景、增强用户信任、促进技术共享与创新、加快企业集成和部署,以及确保社会责任和伦理标准等方面的进步,从而更广泛地融入各行各业,实现AI技术的可持续和负责任的发展。

更多本行业研究分析详见前瞻产业研究院《中国大模型产业发展前景与投资战略规划分析报告》。
同时前瞻产业研究院还提供产业新赛道研究、投资可行性研究、产业规划、园区规划、产业招商、产业图谱、产业大数据、智慧招商系统、行业地位证明、IPO咨询/募投可研、专精特新小巨人申报等解决方案。在招股说明书、公司年度报告等任何公开信息披露中引用本篇文章内容,需要获取前瞻产业研究院的正规授权。
更多深度行业分析尽在【前瞻经济学人APP】私募和股票的区别,还可以与500+经济学家/资深行业研究员交流互动。更多企业数据、企业资讯、企业发展情况尽在【企查猫APP】,性价比最高功能最全的企业查询平台。
 海量资讯、精准解读,尽在新浪财经APP
海量资讯、精准解读,尽在新浪财经APP